技术解码:端侧AI推理的冷热分离架构如何突破算力边界
2024年3月,Kickstarter众筹史上出现了一个标志性事件。TiinyAIPocketLab上线仅5小时,众筹金额突破100万美元。上一个达到此速度的项目,是2022年的拓竹BambuLabX1——后者如今已是营收百亿的独角兽。
从开源引擎到硬件产品的技术演进
这支团队的核心技术积累,可追溯至GitHub上的PowerInfer项目。2024年,该项目斩获9100个star,成为端侧推理加速领域的明星开源成果。TiinyAI正是这一技术积累的商业化载体。
技术架构层面,PowerInfer的核心创新在于冷热参数分离机制。大模型推理过程中,参数激活模式呈现显著差异:热激活参数每次交互都会调用,约占总参数的20%;冷激活参数仅在特定领域查询时激活。基于这一特性,团队设计了异构算力分配方案:热参数置于dNPU(160TOPSASIC)处理,冷参数由SoC(Armv9.2CPU+NPU30TOPS)承载。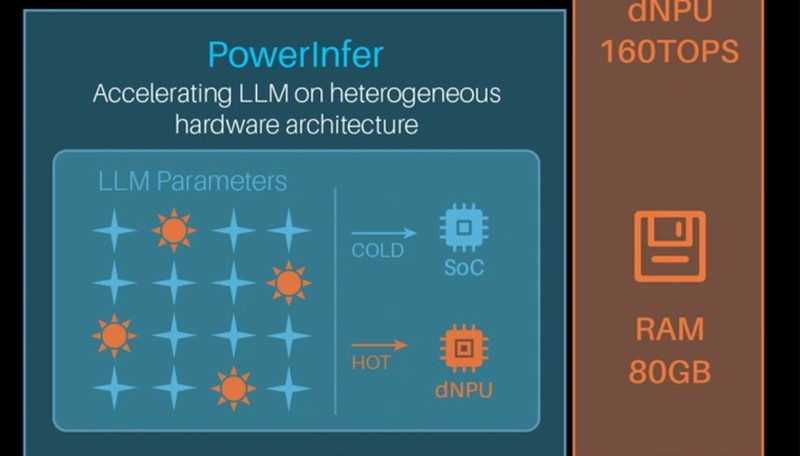
性能实测:端侧100B模型的运行能力边界
官方披露的实测数据揭示了具体性能表现。120BMoE模型在prefill阶段可达300tokens/s,decoding阶段20tokens/s;35Bdense模型prefill约2000tokens/s,decoding45tokens/s。对比人类阅读速度8-12tokens/s,这套方案的输出效率已远超日常使用需求。
功耗控制同样值得关注。30WTDP在300g金属机身内的散热设计,需要定制1.0mmVC均热板配合双风扇模组。FIN与FAN搭接一体化设计,意在解决局域化散热问题,噪音控制在35dB以内。
市场定位:精准切入产品品类真空地带
这款产品的市场逻辑清晰:不做通用计算,只做100B级别模型本地推理。用户画像锁定三类群体:高隐私敏感行业从业者(金融、法律、科研)、已有高性能PC但被大模型抢占算力的极客玩家、尝试过树莓派或Jetson但受困于算力不足的用户。
相比直接采购4090/5090等高端显卡的成本,TiinyAI试图以更低硬件资源运行百亿参数模型。Kickstarter售价1399美元起,截至发稿已众筹295万美元,2093名支持者。
技术质疑与产品逻辑再审视
海外观察者提出若干技术质疑:120BMoE模型每个token仅激活约51亿参数,与"运行1200亿参数模型"存在语义差异;190TOPS算力可能为多计算单元理论峰值累加;80GB内存分布于dNPU与SoC,PCIe带宽或为潜在瓶颈。
对此,团队回应:冷热参数合并的数据量极小,以GPT-OSS-120B为例,每次跨PCIe传输仅约5.625KB,远低于PCIeGen4x4的8GB/s带宽上限。技术价值本身未被质疑,更多是市场营销表述的规范化问题。
结论:端侧AI的品类定义权争夺
TiinyAI的本质,是将AIInfra层面的技术积累,转化为消费级硬件产品。软件调度优于硬件堆料的理念,或将重塑端侧AI设备的竞争格局。8月量产交付后,这款产品能否验证"个人AI工作站"的品类价值,值得持续跟踪。